En este blog de SQL Server dare unas recomendaciones para asi poder realizar una auditoria de base de datos y realizar un correcto seguimiento de los cambios realizados en una tabla. La primera recomendacion que yo les daria seria agregar unos campos adicionales a la estructura de la tabla que seria sometida a una auditoria, algo como:
ModificadoPor varchar(40),
Modificado datetime,
Accion char(1)
Con estos campos que almacenan el valor de quien modifico la fila, la fecha de cambio y la accion que se realizo. De este modo se tiene un registro de los cambios en la tabla.
la segunda recomendacion que yo podria darles seria crear una tabla espejo, es decir no modificar la tabla original, pero crear una tabla con la misma estructura. Osea que si la tabla es 'Facturas', la tabla espejo seria 'Facturas_Auditoria', a la que hay que añadir los campos mencionados anteriormente. Para cada accion en la tabla original se graba una fila en la tabla de auditoria.
Bueno para finalizar con estas dos recomendaciones que yo recomiendo en mi blog queria mencionarles una ventaja principal la cual yo considero que es la mas importante que seria que esto me permitiria a mi y a ustedes en el momento de crearsu base de datos puedan llevar un historial fila por fila, de ese modo se podra saber los cambios que se realizaron en su debida fecha. Bueno tambien seria recomendable decir la desventaja mas importante que yo podria encontrar y seria que podria ocurrir una sobrecarga considerable de transacciones y por lo mismo un aumento del tamaño de la Base de Datos. Bueno se recomienda que para crear este tipo de campos solo se hagan en las tablas primarias o tambien llamadas o consideradas como las mas importantes y no en todas, asi podriamos evitar esta sobrecarga, muchas gracias por su visita e inquietudes y espero saber muy pronto de ustedes, hasta luego.
martes, 16 de noviembre de 2010
Caso Practico de Carga masiva Incremental en SQL Server 2000
Información recopilada de la siguiente dirección, para mayor información visitar la siguiente url:
http://www.microsoft.com/spain/technet/recursos/articulos/incbulkload.mspx
Resumen
La carga masiva incremental es la carga de datos en una tabla que no está vacía. La cuestión principal durante la carga masiva incremental es si deben eliminarse previamente los índices. La respuesta depende de varios factores. En este documento se intenta responder a esta pregunta mediante un caso práctico de carga masiva incremental en el que se utiliza la instrucción BULK INSERT en un sistema representativo de ayuda a la toma de decisiones (DSS) que ejecuta Microsoft® SQL Server™ 2000 en Microsoft Windows 2003 Server®. Debe considerar los resultados presentados en este documento como recomendaciones y no como respuestas absolutas, ya que dependerán del hardware (por ejemplo, el número de CPU utilizadas, la E/S y el ancho de banda de red), de la distribución de los datos en la tabla y de los archivos de datos y parámetros utilizados en la instrucción BULK INSERT. Todas las pruebas se realizaron en un sistema de hardware de Hewlett-Packard (para obtener más información sobre los entornos de prueba, consulte el Apéndice A, "Entornos de prueba"). En este documento se ofrecen recomendaciones generales para los siguientes escenarios:| • | Tabla de destino sin índices:
| ||||||
| • | Tabla de destino con un índice agrupado:
| ||||||
| • | Tabla de destino con un solo índice no agrupado:
| ||||||
| • | Tabla de destino con un índice agrupado y varios índices no agrupados:
|
Con algunas excepciones, estas recomendaciones son válidas cuando se realiza la carga masiva de datos mediante la utilidad bcp y los Servicios de transformación de datos (DTS). En este documento no se tratan las excepciones.
Introducción
En un entorno DDS típico, se cargan datos periódicamente de orígenes externos (como un sistema de procesamiento de transacciones en línea [OLTP]). Las tablas tienen normalmente varios índices no agrupados además de un índice agrupado para el rendimiento óptimo de las consultas. Estos índices dan lugar a una carga más lenta en comparación con la carga de datos en una tabla sin índices, ya que cada inserción requiere una actualización de todos los índices. En este documento se describen las prácticas recomendadas para la carga masiva incremental y se explican los motivos en los que se basan estas prácticas recomendadas mediante datos de prueba de cuatro escenarios distintos. Las recomendaciones se aplican principalmente para obtener el máximo rendimiento de carga masiva. La carga masiva también es habitual en las cargas de trabajo de las aplicaciones OLTP; no es exclusiva de las cargas de trabajo de las aplicaciones DSS. Las recomendaciones proporcionadas en este documento se aplican igualmente a las cargas de trabajo de las aplicaciones OLTP.Descripción del funcionamiento de la carga masiva
Son varios los factores que afectan al rendimiento de las operaciones de carga masiva (por ejemplo, la instrucción BULK INSERT y la utilidad bcp). En las siguientes secciones se describen estos factores y se sugieren formas de mejorar el rendimiento. Los parámetros descritos se aplican a la instrucción BULK INSERT. Existen también parámetros similares para otros métodos de carga masiva.Método de carga masiva
SQL Server admite tres métodos de carga masiva:| • | La inserción masiva como un comando de Transact-SQL |
| • | La utilidad bcp |
| • | DTS |
La instrucción BULK INSERT de Transact-SQL se ejecuta en el mismo proceso que SQL Server, por lo que comparte el mismo espacio de direcciones de memoria. Como el que abre los archivos de datos es un proceso de SQL Server, no es posible la copia de datos entre procesos.
Los ejecutables de BCP y DTS se ejecutan fuera de proceso y, por tanto, requieren la copia de datos entre procesos y el cálculo de referencia de parámetros para mover los datos entre espacios de memoria de procesos. El cálculo de referencia de datos entre procesos es el proceso de convertir parámetros de una llamada a un método en una secuencia de bytes y puede agregar una sobrecarga considerable a la CPU. Con Bulk Insert, puede omitir estos pasos y utilizar directamente OLE-DB. Sin embargo, a diferencia de Bulk Insert, BCP analiza los datos y los convierte en formato de almacenamiento nativo en el proceso del cliente. Esto puede constituir una ventaja en cuanto al rendimiento frente a Bulk Insert, si SQL Server se ejecuta en un equipo con un único procesador, ya que el proceso de SQL Server se sobrecarga con el análisis y la conversión de los datos cuando se ejecuta la instrucción BULK INSERT. Según el tipo de procesamiento y de copia, puede observar un aumento del 20 por ciento o una merma de hasta el 100 por cien (por ejemplo, cuando se realiza una carga masiva de datos LOB) en el rendimiento de carga masiva con BCP frente a Bulk Insert.
Para este caso práctico, hemos elegido el comando Bulk Insert para las operaciones de carga masiva.
Modo de recuperación de la base de datos
Las operaciones de carga masiva pueden realizar un registro optimizado (es decir, sólo se registran las asignaciones de páginas de registro y no los datos reales ni las filas de índice) en determinadas condiciones. Si la base de datos está configurada en modo de recuperación completa, el registro especializado para las operaciones en bloque y de ordenación no está habilitado. Si es posible, debe establecer el modo de recuperación de la base de datos en Recuperación de registro masivo (configuración preferida) o Recuperación simple durante las operaciones de carga masiva.Nota la configuración del modo de recuperación de la base de datos es sólo una de las condiciones para habilitar el registro masivo optimizado. Éste depende también de otros factores descritos más adelante en este documento.
Esquema de la tabla de destino
El esquema de la tabla de destino afecta a los planes de consultas de las operaciones de carga masiva, al registro optimizado y a la carga masiva simultánea y, en última instancia, repercute en el rendimiento de la operación de carga masiva. En las siguientes secciones se explican los elementos del esquema de la tabla de destino que afectan al plan de consultas.Índices
La mayoría de las tablas contienen índices; la tabla de destino de la operación de carga masiva no es una excepción. Sin embargo, la inclusión de índices en la tabla de destino afecta al rendimiento de la carga masiva. Hay dos opciones para los índices de la tabla de destino: borrar uno de ellos o varios, realizar una carga masiva de los datos y volver a crear después los índices borrados, o no borrar ningún índice. Tenga en cuenta las siguientes consideraciones cuando la tabla de destino:| • | No contenga índices Cuando la tabla de destino no contenga índices y se haya especificado TABLOCK, puede ejecutar varios comandos de carga masiva simultáneamente. Estas cargas masivas simultáneas utilizan un bloqueo de actualización masiva en el nivel de tabla, que inserta los datos sin bloquear otras sesiones. Si utiliza TABLOCK sin índices, también se pueden realizar optimizaciones de registro masivo. No importa si la tabla está vacía o llena. Ésta es la forma más rápida de realizar una carga masiva de datos. Sin embargo, el bloqueo de actualización masiva entra en conflicto con los bloqueos de recursos normales y los bloqueos exclusivos. Si no se ha especificado TABLOCK, también puede ejecutar simultáneamente varios comandos de carga masiva, pero cada uno de estos comandos utiliza un bloqueo normal, como el que emplea la instrucción Insert de Transact-SQL, y no se pueden realizar optimizaciones de registro masivo. |
| • | Contenga un único índice no agrupado o agrupado Cuando la tabla de destino contiene un índice, la carga masiva simultánea con el bloqueo de actualización masiva no se puede realizar con TABLOCK. Nota aún es posible ejecutar cargas masivas simultáneas sin especificar TABLOCK (como se ha descrito en el escenario sin índices) y para ello se utiliza el bloqueo normal. Sin embargo, puede que las sesiones de carga masiva simultánea se bloqueen. En ese caso, las optimizaciones de registro masivo sólo están disponibles cuando la tabla está vacía inicialmente y la carga masiva se realiza en un único lote. Nota si realiza la carga masiva de datos en varios lotes en esta situación, la optimización de registro masivo no estará disponible a partir del segundo lote, ya que la tabla no estará vacía una vez ejecutado correctamente el primer lote. Un plan de consultas típico en una tabla con un índice agrupado es (archivoDatos-Examinar) --> (Ordenar por clave agrupada) --> (Insertar en índice agrupado). Para evitar la ordenación si los datos del archivo de datos ya están ordenados por columnas de clave de índice agrupado, especifique una indicación ORDER. De igual forma, un plan de consultas típico en una tabla con un único índice no agrupado es (archivoDatos-Examinar) --> (Insertar datos en la tabla) --> (Ordenar por clave no agrupada) --> (Insertar en índice no agrupado). Nota aunque los datos de entrada estén ordenados por columnas de clave no agrupada, no se puede eliminar la ordenación. La indicación ORDER sólo se puede aplicar al insertar datos en la tabla base (con índice agrupado). No se tiene en cuenta en los demás casos. |
| • | Contenga un índice agrupado y varios índices no agrupados Cuando la tabla de destino contiene un índice agrupado y varios índices no agrupados, la carga masiva simultánea con el bloqueo de actualización masiva no se puede realizar con TABLOCK. Nota aún es posible ejecutar cargas masivas simultáneas sin especificar TABLOCK (como en el escenario sin índices) y para ello se utiliza el bloqueo normal. Sin embargo, puede que las sesiones de carga masiva simultánea se bloqueen. En ese caso, las optimizaciones de registro masivo sólo están disponibles cuando la tabla está vacía inicialmente y la carga masiva se realiza en un único lote. Nota si realiza la carga masiva de datos en varios lotes en esta situación, la optimización de registro masivo no estará disponible a partir del segundo lote, ya que la tabla no estará vacía una vez ejecutado correctamente el primer lote. Un plan de consultas típico en este caso es más complejo, pero la parte inicial es la misma que en el caso de un único índice no agrupado o de un índice agrupado. --> Poner en cola --> Ordenar por clave no agrupada --> insertar en índice 1 no agrupado (plan anterior) -->| ....... --> Poner en cola --> Ordenar por clave no agrupada --> insertar en índice 2 no agrupado Una vez creado el índice agrupado, todos los atributos necesarios para crear índices no agrupados se ponen en cola. Estos atributos incluyen todas las columnas de clave de los índices no agrupados y las columnas de clave agrupada. Las columnas de la clave de índice agrupado se utilizan para apuntar a la fila de datos de las páginas secundarias del índice no agrupado. En el plan de consultas anterior que representa una carga masiva, los datos de cada índice no agrupado se insertan en paralelo. |
Cuando la tabla de destino está vacía, es lógico crear índices después de que haya terminado la carga masiva por dos motivos. En primer lugar, puede realizar una carga masiva simultánea con el bloqueo de actualización masiva y el registro masivo optimizado. En segundo lugar, puede crear cada índice en paralelo.
Nota en este documento, "en paralelo" hace referencia a un único comando ejecutado por varios subprocesos. Por ejemplo, varios subprocesos pueden ejecutar una única instrucción CREATE INDEX de Transact-SQL. En este caso, la instrucción BULK INSERT no se puede ejecutar en paralelo. Debe llamar a varias instrucciones BULK INSERT para cargar los datos en paralelo.
Restricciones
Las restricciones se comprueban para cada fila insertada. Si procede, se recomienda deshabilitar la comprobación de restricciones. La única restricción que se puede deshabilitar es la restricción de comprobación. No se puede deshabilitar la restricción de unicidad, la restricción de clave principal/clave externa ni la restricción NOT NULL. Cuando la opción de restricción de comprobación se vuelva a habilitar, SQL Server deberá comprobar toda la tabla para volver a validar las restricciones. Por este motivo, no se recomienda deshabilitar restricciones durante la carga masiva incremental, ya que es más laborioso volver a validar la restricción para toda la tabla que aplicar restricciones a los datos incrementales.Una situación en la que puede ser conveniente deshabilitar restricciones es cuando los datos de entrada contienen filas que infringen las restricciones. Al deshabilitar las restricciones, puede cargar los datos y utilizar después instrucciones de Transact-SQL para limpiarlos.
Desencadenadores
Si se han definido desencadenadores para las operaciones de inserción en la tabla de destino, se activarán para cada lote finalizado. Si procede, deshabilite la ejecución de desencadenadores durante la operación de carga masiva.TABLOCK
La instrucción BULK INSERT acepta la indicación TABLOCK, que permite al usuario especificar el comportamiento de bloqueo que se va a utilizar.Cuando la carga masiva se realiza en un montón, TABLOCK especifica que se utilice el bloqueo de nivel de tabla de actualización masiva durante la carga masiva. Esto permite mejorar el rendimiento de la operación de carga masiva, ya que se reduce el conflicto de bloqueo en la tabla. Asimismo, TABLOCK es un parámetro obligatorio para el registro masivo cuando el modo de recuperación de la base de datos está configurado en REGISTRO MASIVO o SIMPLE.
Cuando la carga masiva se realiza en una tabla con uno o varios índices, TABLOCK impone un bloqueo de tabla X a las operaciones de carga masiva de forma que no sea posible la carga masiva simultánea.
Si no especifica TABLOCK, la carga masiva no adquiere el bloqueo de tabla, sino el bloqueo en filas o páginas. Sin embargo, los bloqueos de filas o páginas se pueden trasladar al bloqueo X en función del tamaño del lote y de la actividad simultánea en la tabla de destino. SQL Server intenta trasladar los bloqueos de filas o páginas al nivel de tabla si el número de bloqueos es mayor que 5.000.
En la Tabla 1 se describe el comportamiento de registro y bloqueo cuando la tabla de destino no está vacía (es decir, cuando la carga masiva es incremental).
Tabla 1 Comportamiento de registro y bloqueo en una tabla de destino que no está vacía
| Esquema de tabla | TABLOCK | Tipo de registro | Carga masiva simultánea |
Montón (incluidos datos LOB) | Sí | Registro masivo | Sí (bloqueo de actualización masiva) |
Montón (incluidos datos LOB) | No | Registro completo | Sí (bloqueo X normal en filas o páginas) |
Tabla con índices | Sí | Registro completo | No |
Tabla con índices | No | Registro completo | Sí (bloqueo X normal en filas o páginas) |
Nota en el esquema de tabla, el término montón hace referencia a una tabla sin índices agrupados o no agrupados. Se pueden utilizar datos LOB aunque estén representados internamente como un índice por motivos de asignación.
Nota la carga masiva simultánea hace referencia a varios comandos de carga masiva, cada uno con su propia secuencia de datos. Si se especifica TABLOCK, el comando de carga masiva espera a adquirir el bloqueo de tabla. Sin embargo, si TABLOCK no se ha especificado, cada comando de carga masiva adquiere un bloqueo de filas o páginas (siempre que no se haya producido el traslado de bloqueo), según cómo se haya definido el nivel de bloqueo en la tabla.
Carga masiva simultánea
La carga masiva suele estar limitada por la CPU. Por tanto, si SQL Server se ejecuta en un equipo con varios procesadores, observará un mayor rendimiento de la carga masiva cuando se invoquen simultáneamente varios comandos de carga masiva, siempre que no haya bloqueos. Asimismo, durante la carga masiva, existe un bloqueo especial de nivel de tabla (bloqueo de actualización masiva) cuando se especifica TABLOCK. Este bloqueo funciona como un bloqueo exclusivo porque bloquea el acceso a la tabla a través de instrucciones normales de Transact-SQL, pero los subprocesos de carga masiva simultánea no se bloquean. El bloqueo de actualización masiva sólo está disponible en el montón (es decir, en una tabla sin índices) y proporciona el rendimiento de carga simultánea óptimo para esta situación. En la Tabla 1 se describen las condiciones para la carga masiva simultánea.Nota no es necesario que la base de datos tenga el modo de recuperación SIMPLE o REGISTRO MASIVO para la carga masiva simultánea.
Para ejecutar la carga masiva simultáneamente, necesita emitir varios comandos de carga masiva de forma que cada uno de ellos lea sus propios datos. Los comandos de carga masiva múltiples no pueden leer los mismos datos.
Orden de los datos de entrada
Si los datos de entrada está ordenados por la columna de clave agrupada, se elimina la ordenación, como se ha descrito en el plan de consultas para un índice no agrupado o un índice agrupado en la sección "Índices", anteriormente en este documento.BATCHSIZE
La configuración predeterminada de BATCHSIZE es la longitud del archivo de entrada para una instrucción BULK INSERT. Cuando se utiliza otro valor distinto al predeterminado, la carga masiva se divide en una o varias transacciones. Cada transacción inserta hasta BATCHSIZE número de filas. Un lote de tamaño más pequeño proporciona las siguientes ventajas:| • | Cuando existen índices, un lote pequeño reduce la memoria necesaria para la ordenación. Durante la carga masiva simultánea, puede reducir también el bloqueo en función del modelo de datos y de la distribución en los archivos de datos de entrada. |
| • | En caso de que se produzca un error, tendrá que volver a cargar sólo los datos a partir del último lote que no pudo ejecutarse. Por ejemplo, si la carga masiva dura tres horas y el error se produce casi al final, sólo tendrá que volver a cargar el último lote, en lugar de iniciar de nuevo toda la carga masiva. |
Modo de datos
Los datos del archivo de datos pueden tener formato de carácter o nativo (es decir, representación binaria). La carga de datos almacenados en formato de carácter requiere el análisis y su posterior conversión al formato de almacenamiento nativo basado en el tipo de columna de la tabla de destino, lo que requiere recursos del servidor. El formato de carácter es el formato más común para los datos, pero es más eficaz cargar datos que estén disponibles en el formato nativo.Tamaño de los datos de entrada
El tamaño de los datos de entrada es importante en caso de que haya índices. Cuando se crea un índice agrupado, SQL Server ordena los datos y aumenta su tamaño. Cuanto mayor sea el tamaño de los datos de entrada, mayor será la memoria necesaria (es posible que la ordenación se tenga que ejecutar en varios pasos). Lo mismo ocurre con los índices no agrupados, salvo que en este caso el tamaño de los datos que se van a ordenar depende del tamaño de la clave de índice y del número de filas. Puede controlar el tamaño de los datos especificando un tamaño de lote más pequeño. Asimismo, en función del tamaño de los datos que desee cargar, la información estadística sobre la tabla de destino puede cambiar considerablemente. Es recomendable que vuelva a crear las estadísticas después de la operación de carga masiva, especialmente si ha deshabilitado la regeneración automática de estadísticas.Escenarios
En cargas de trabajo DSS, conviene utilizar escenarios de carga masiva incremental en los que haya una tabla de destino con uno o varios índices. También es conveniente utilizar un escenario en el que la carga masiva se realice en una tabla sin índices, porque en algunas situaciones (que reciben el nombre de punto de convergencia) es aconsejable borrar todos los índices de la tabla, realizar la carga masiva incremental y volver a crear los índices, en lugar de realizar la carga masiva incremental con índices incluidos.Un punto de convergencia se define como la proporción de datos incrementales en relación con los datos existentes en la tabla de destino por debajo de la cual se puede obtener un mejor rendimiento de la carga masiva incremental sin borrar los índices. Dicho de otro modo, si conoce el punto de convergencia de una tabla de destino específica, puede determinar si debe borrar o no los índices antes de realizar la carga masiva de los datos.
La clave, por tanto, es determinar cuál es el punto de convergencia. El punto de convergencia depende de una serie de variables, como el esquema de la tabla, los recursos de hardware y la distribución de los datos. Sin embargo, para un sistema con niveles de recursos y carga homogéneos, puede ser conveniente determinar el punto de convergencia para definir una buena estrategia de carga masiva.
Nota si cambia alguno de los factores dependientes, tendrá que volver a calcular el punto de convergencia. En este documento, el punto de convergencia se calcula para cada escenario. Es absolutamente recomendable que considere las prácticas recomendadas descritas en este documento como recomendaciones generales; su experiencia podría ser diferente debido a las diferencias de hardware y software.
Las pruebas de los escenarios presentados en este documento se basan en la tabla definida en el Apéndice A, "Entornos de prueba". Los datos incluidos en la carga masiva estaban almacenados en modo carácter. Al cargar los datos en modo carácter, se produce una sobrecarga de la CPU, ya que éstos deben analizarse y convertirse en el tipo de columna de la tabla de destino antes de cargarse. Puede eliminar esta sobrecarga si carga los datos en modo nativo.
Carga masiva incremental sin índices
Resumen
Los resultados de las pruebas para este escenario sugieren utilizar comandos de carga masiva simultáneos con el tamaño de lote predeterminado y la indicación TABLOCK para obtener la máxima velocidad de carga. Para ello, se puede ejecutar el mismo número de comandos Bulk Insert que el número de procesadores mediante la indicación TABLOCK. La base de datos debe estar configurada en modo de recuperación de registro masivo.Comando de carga masiva
Se ha utilizado el siguiente comando para realizar la carga masiva de los datos para cada uno de los ocho comandos de carga masiva simultáneos:BULK INSERT tabla_hechos <archivo-datos> WITH (TABLOCK)
Parámetros:
| • | TABLOCK: para ejecutar varios comandos de carga masiva simultáneamente. La consulta obtiene un bloqueo de actualización masiva. |
| • | BATCHSIZE: no especificado. Cada comando de carga masiva carga los datos de un único lote. |
Resultados
El rendimiento de la carga aumenta linealmente con el número de procesadores. No se detectó ningún cuello de botella en la E/S. Sin embargo, no había otra carga de trabajo en el sistema. Durante la carga masiva, la utilización de la CPU fue casi del 100%. En la Figura 1 se indica el rendimiento combinado obtenido con ocho comandos de carga masiva simultáneos.
Figura 1 Carga masiva incremental en un montón
Recomendaciones
A continuación, se incluyen algunas recomendaciones para obtener un rendimiento óptimo en la carga masiva incremental:| • | Utilice la configuración predeterminada para el tamaño del lote. Con la configuración predeterminada, el tamaño del lote se equipara al tamaño del archivo de datos y se reduce la sobrecarga que se produce al abrir y cerrar los archivos. | ||||||
| • | Utilice la indicación TABLOCK para mejorar el rendimiento. La indicación TABLOCK mejora el rendimiento al:
|
Carga masiva incremental con un único índice agrupado
Resumen
Es aconsejable conservar el índice agrupado durante la carga masiva incremental. En este escenario, se utilizaron los dos planes siguientes:| • | Plan A La carga masiva incremental se realizó borrando el índice agrupado, cargando los datos en la tabla de destino y volviendo a crear el índice agrupado. |
| • | Plan B La carga masiva incremental se realizó sin borrar el índice agrupado. |
Los resultados de las pruebas sugieren que es conveniente cargar los datos con el índice agrupado intacto a no ser que el número de datos incrementales sea mayor que el número de datos de la tabla original.
Comando de carga masiva
Plan A
Se ejecutaron los siguientes comandos en orden:| 1. | Borrar índice agrupado tabla_hechos.ia. (Ejecutado mediante un único subproceso. No es posible el paralelismo.) |
| 2. | Bulk Insert tabla_hechos <archivo-datos>. (Ejecutado con ocho comandos de carga masiva simultáneos.) |
| 3. | crear índice agrupado ic en tabla_hechos(id_pedido). (Ejecutado con paralelismo de ocho vías.) |
Parámetros para Bulk Insert:
| • | TABLOCK: Para realizar la carga masiva simultáneamente. Obtiene un bloqueo de actualización masiva. |
| • | BATCHSIZE: No especificado. Cada comando de carga masiva carga los datos de un único lote. |
Plan B
Bulk Insert tabla_hechos <archivo-datos>. (El tamaño del lote se estableció en 5.000 filas.) (Ejecutado con ocho comandos de carga masiva simultáneos sin borrar el índice agrupado.)Parámetros para Bulk Insert:
| • | TABLOCK: No especificado. Si se especificara, el resultado sería un bloqueo de tabla X. |
| • | BATCHSIZE: Especificado para reducir el conflicto de bloqueo. |
Resultados
Para el Plan A, se midió el rendimiento para el borrado y creación de un índice agrupado. Una vez borrado el índice agrupado, la carga incremental consistió básicamente en la carga de datos en un montón. Para obtener más información sobre la carga masiva sin índices, consulte "Carga masiva incremental sin índices" anteriormente en este documento.Como se ilustra en la Figura 2, el resultado fue una escalabilidad casi lineal al crear el índice agrupado. Para crear el índice agrupado se utilizó un paralelismo de ocho vías. Como el índice no cabía en memoria, la ordenación se realizó en varios pasos.

Figura 2 Crear o borrar un índice agrupado con un tamaño de tabla mayor
| • | Número de procesadores mostrados por el sistema operativo, que se define mediante la opción numproc de boot.ini. |
| • | Afinidad de CPU de SQL Server, que se define mediante la opción de comando sp_configure. |
| • | Grado máximo de paralelismo para SQL Server, que se define mediante la opción de comando sp_configure. |
| • | Recursos del sistema disponibles al iniciarse la creación del índice, que se determinan de forma dinámica. Si el sistema está ocupado, el grado de paralelismo se ajusta al número menor. Una vez iniciada la creación del índice, el grado de paralelismo no cambia. Nota el tiempo necesario para crear un índice agrupado depende de varios factores, como el ancho de banda de E/S, el número de procesadores, la memoria disponible, el tamaño de la tabla, el tamaño de la clave agrupada, el modo de recuperación de la base de datos y la carga actual en el sistema. En las pruebas presentadas en este documento, la creación del índice estaba limitada por la CPU. |
Resulta costoso borrar un índice agrupado, porque una vez borrado, el motor de base de datos debe actualizar el espacio disponible para cada página de datos. Esto implica un análisis completo de la tabla. Las pruebas mostraron que borrar un índice agrupado era más costoso (en términos de tiempo) que crear el mismo índice agrupado. Esto se debe a que al crear el índice se pueden utilizar los ochos procesadores mediante planes de consultas en paralelo, mientras que el borrado del índice agrupado se realiza en un único subproceso.
Para el Plan B, las pruebas indicaron que la velocidad de carga permanece constante al cargar tablas con un único índice agrupado (Figura 3). El rendimiento de la carga permanece constante durante toda la fase de carga, porque el tamaño de la tabla varía de 5 gigabytes (GB) a 1 terabyte. Como se ejecutaron ocho comandos de carga masiva simultáneos, no se produjo traslado de bloqueo.

Figura 3 Carga masiva incremental
Nota en la prueba presentada en este documento, los datos existentes y los datos incrementales estaban distribuidos uniformemente en columnas de clave agrupada. Si se cambia la distribución de los datos, se puede producir un conflicto importante. Puede reducir el conflicto disminuyendo el tamaño del lote o el número de comandos de carga masiva simultáneos.
En la Figura 4 se ilustra el punto de convergencia cuando aumenta el tamaño de los datos incrementales. El tamaño inicial de la tabla era 91 GB para esta prueba. El tamaño inicial no debería afectar al punto de convergencia, ya que se basa en el porcentaje del tamaño inicial de la tabla. Para cada punto trazado, el tiempo de carga incluye el tiempo empleado en realizar todos los pasos del plan. Por ejemplo, el tiempo total empleado para cargar un 200 por ciento adicional de los datos en esta tabla fue de 26.663 segundos para el Plan A: 10.391 segundos para borrar el índice agrupado, 4.203 segundos para cargar 182 GB de datos adicionales en la tabla sin índice y 12.069 segundos para volver a crear el índice agrupado en la tabla con 273 GB de datos. Se tardó más tiempo en crear el índice agrupado que en borrarlo, ya que el tamaño de la tabla aumentó un 200 por ciento después de la carga incremental de los datos.

Figura 4 Punto de convergencia para la carga masiva incremental con un índice agrupado
Recomendaciones
A continuación, se incluyen algunas recomendaciones para obtener un rendimiento óptimo en la carga masiva incremental. Estas recomendaciones se aplican al tipo de carga de trabajo que se probó en el caso práctico presentado en este documento. Proporcionan también un buen punto de partida para otros tipos de carga de trabajo:| • | A menos que el tamaño de la carga incremental sea considerablemente mayor que el tamaño actual de la tabla de destino, lo más probable es que se obtenga un mejor rendimiento de carga masiva con el Plan B. | ||||||||||||
| • | Compruebe la distribución de la clave agrupada en la tabla de destino y los datos incrementales. Si los valores de la clave agrupada no se solapan, puede realizar la carga masiva de datos en paralelo con un bloqueo mínimo o sin bloqueo. Normalmente, en un escenario de almacén de datos, los datos incrementales se concentran en la parte final de la clave agrupada, lo que puede dar lugar a un conflicto mayor con comandos de carga masiva simultáneos. En la Tabla 2 se muestra cómo el rendimiento de la carga aumenta con varios comandos de carga masiva simultáneos. Las pruebas muestran que el rendimiento de carga masiva no aumenta linealmente con el número de procesadores. Esto se debe al bloqueo o conflicto de bloqueo entre los distintos comandos de carga masiva y a la sobrecarga de transacciones o tamaños de lote pequeños, incluido el cierre y la apertura de archivos de datos de entrada. El rendimiento de la carga casi se duplica cuando en lugar de un único comando de carga masiva se utilizan ocho comandos de carga masiva simultáneos. Sin embargo, el uso total de CPU aumenta del 12 por ciento (es decir, una CPU al 100 por cien) al 95 por ciento: un aumento ocho veces mayor. Se eligieron diferentes tamaños de lote en función del número de comandos de carga masiva simultáneos necesarios para obtener un rendimiento óptimo. Por ejemplo, para el comando de carga masiva único, se utilizó un único lote, mientras que para los ocho comandos de carga masiva simultáneos se utilizó un tamaño de lote de 5.000 filas. Tabla 2 Aumento del rendimiento de carga con varios comandos de carga masiva simultáneos
| ||||||||||||
| • | Utilice un tamaño de lote pequeño para reducir el conflicto si se solapan los datos. Cada lote de la carga masiva se ejecuta como una transacción independiente. Por tanto, un tamaño de lote pequeño limitará el número de filas bloqueadas y reducirá el bloqueo. Además, un tamaño de lote pequeño permite la ordenación en memoria por columna de clave agrupada de los datos que se van a insertar en la tabla de destino. |
Carga masiva incremental con un único índice no agrupado
Resumen
En este escenario, se probaron los siguientes planes:| • | Plan A La carga masiva incremental se realizó borrando el índice no agrupado, cargando los datos en la tabla de destino y volviendo a crear el índice. |
| • | Plan B La carga masiva incremental se realizó sin borrar el índice no agrupado. |
En este escenario, es mejor mantener el índice no agrupado durante la carga masiva incremental si el tamaño de los datos incrementales es similar al tamaño inicial de la tabla. Si es considerablemente mayor, es mejor borrar el índice antes de la carga y volver a crearlo.
Comando de carga masiva
Plan A
Se ejecutaron los siguientes comandos en orden:| 1. | Borrar índice no agrupado tabla_hechos.ina_1. (Ejecutado en un único subproceso.) |
| 2. | Bulk Insert tabla_hechos <archivo-datos> con TABLOCK. (Ejecutado con ocho comandos de carga masiva simultáneos.) |
| 3. | Crear índice no agrupado ina_1 en tabla_hechos(id_pedido). (Ejecutado con paralelismo de ocho vías.) |
Parámetros:
| • | TABLOCK: Para ejecutar los comandos de carga masiva simultáneamente. Obtiene un bloqueo de actualización masiva. |
| • | BATCHSIZE: No especificado. Cada comando de carga masiva carga los datos de un único lote. |
Plan B
Bulk Insert tabla_hechos <archivo-datos> con batchsize=5000. (Ejecutado con ocho comandos de carga masiva simultáneos.)Parámetros:
| • | TABLOCK: No especificado. Si se especificara, el resultado sería un bloqueo de tabla X. |
| • | BATCHSIZE: Especificado para reducir el conflicto de bloqueo. |
Resultados
Para el Plan A, el borrado de un índice no agrupado en SQL Server 2000 es instantáneo. Una vez borrado el índice no agrupado, la carga incremental consiste básicamente en la carga de datos en un montón. Consulte el escenario anterior. Para obtener más información sobre el rendimiento de la carga masiva incremental en un montón, consulte "Carga masiva incremental sin índices" anteriormente en este documento.Dado el pequeño tamaño de la entrada de índice y la escasa profundidad del árbol B, la función es casi lineal. En la Figura 5 se ilustra cómo el tiempo para crear un índice no agrupado aumenta casi linealmente con el tamaño de los datos de la tabla.

Figura 5 Tiempo necesario para crear un índice no agrupado
Para el Plan B, la velocidad de carga con sólo un índice no agrupado fue constante. Como se ilustra en la Figura 6, el rendimiento de la carga permaneció constante durante toda la fase de carga desde 5 GB a 1 terabyte (sólo el tamaño de los datos, sin incluir el índice) para la misma tabla con un único índice no agrupado.

Figura 6 Rendimiento en comparación con el tamaño de los datos existentes

Figura 7 Punto de convergencia para la carga masiva incremental
Recomendaciones
Estas recomendaciones se aplican al tipo de carga de trabajo que se probó en el caso práctico presentado en este documento. Estas recomendaciones proporcionan un buen punto de partida para otros tipos de carga de trabajo. Las recomendaciones para una velocidad de carga masiva óptima son:| • | Conserve el índice no agrupado durante la carga masiva incremental si el tamaño de los datos incrementales es similar al de la tabla de destino. De lo contrario, es mejor borrar el índice antes de la carga y volver a crearlo. | ||||||||||||
| • | Utilice un tamaño de lote pequeño para reducir el conflicto si se solapan los datos. Cada lote de la carga masiva se ejecuta como una transacción independiente, por lo que un tamaño de lote pequeño limita el número de filas bloqueadas y reduce por tanto el bloqueo. Además, un tamaño de lote pequeño permite realizar ordenaciones en memoria por columna de clave no agrupada de los datos que se van a insertar en la tabla de destino. | ||||||||||||
| • | Como vimos en la tabla con un índice agrupado, si realiza la carga masiva sin borrar el índice debido a un bloqueo o conflicto de bloqueo, la carga masiva no aumenta linealmente al aumentar la concurrencia. En la Tabla 3 se muestra que el rendimiento de la carga masiva aumentó sólo 2,5 veces con ocho comandos de carga masiva simultáneos. Por tanto, a menos que no haya peticiones que compitan por los procesadores, las ventajas de ejecutar comandos de carga masiva simultáneos serán pocas. Para obtener un rendimiento óptimo en la prueba presentada en este documento, se seleccionaron diferentes tamaños de lote en función del número de comandos de carga masiva simultáneos. Por ejemplo, para el comando de carga masiva único, se utilizó un único lote, mientras que para los ocho comandos de carga masiva simultáneos se utilizó un tamaño de lote de 5.000 filas. Tabla 3 Aumento del rendimiento de la carga masiva
|
Carga masiva incremental con un índice agrupado y varios índices no agrupados
Resumen
En este escenario, se probaron los siguientes planes:| • | Plan A Borrar todos los índices, incluido el índice agrupado, cargar los datos y volver a crear todos los índices. | ||||
| • | Plan B Borrar todos los índices no agrupados, cargar los datos con el índice agrupado existente y volver a crear todos los índices no agrupados. La decisión de mantener el índice agrupado intacto y de borrar los índices no agrupados se tomó por los siguientes motivos:
| ||||
| • | Plan C Carga masiva incremental sin borrar ningún índice. |
Los resultados de las pruebas indicaron que el Plan B es el recomendado, salvo si los datos incrementales son un porcentaje muy pequeño de los datos existentes.
Comando de carga masiva
Plan A
Se ejecutaron los siguientes comandos en orden:| 1. | Borrar todos los índices no agrupados. |
| 2. | Borrar el índice agrupado (ejecutado con un único subproceso). |
| 3. | Bulk Insert tabla_hechos <archivo-datos> (ejecutado con ocho comandos de carga masiva simultáneos). |
| 4. | Crear el índice agrupado. |
| 5. | Crear todos los índices no agrupados. |
Parámetros de Bulk Insert al realizar la carga en un montón:
| • | TABLOCK: Para ejecutar los comandos de carga masiva simultáneamente. Obtiene un bloqueo de actualización masiva. |
| • | BATCHSIZE: No especificado. Cada comando de carga masiva carga los datos de un único lote. |
Plan B
Se ejecutaron los siguientes comandos en orden:| 1. | Borrar todos los índices no agrupados. |
| 2. | Bulk Insert tabla_hechos <archivo-datos> con un tamaño de lote de 5.000. (Ejecutado con ocho comandos de carga masiva simultáneos.) |
| 3. | Crear todos los índices no agrupados. |
Parámetros para Bulk Insert:
| • | TABLOCK: No especificado. Si se especificara, el resultado sería un bloqueo de tabla X. |
| • | BATCHSIZE: Especificado para reducir el conflicto de bloqueo. |
Plan C
Comando ejecutado sin borrar ningún índice.Bulk Insert tabla_hechos <archivo-datos>. (Ejecutado con un único comando de carga masiva.)
Parámetros para Bulk Insert:
| • | TABLOCK: No especificado. Si se especificara, el resultado sería un bloqueo de tabla X. |
| • | BATCHSIZE: Se utilizó un tamaño de lote de 20.000.000 filas. |
Resultados
Para el Plan A, el tiempo empleado incluye la suma del tiempo necesario para borrar todos los índices no agrupados y el índice agrupado, para realizar la carga masiva de los datos en el montón y para volver a crear los índices agrupados y no agrupados. Una vez borrados todos los índices, la carga incremental consiste básicamente en la carga de datos en un montón. Consulte los escenarios anteriores. Para obtener más información sobre el rendimiento durante la carga masiva incremental en un montón, consulte la Figura 1 anteriormente en este documento. Para obtener más información sobre el rendimiento al borrar y volver a crear índices, consulte la Figura 2 y 5 anteriormente en este documento.Para el Plan B, el tiempo empleado incluye la suma del tiempo necesario para borrar todos los índices no agrupados, para realizar la carga masiva de los datos en la tabla con el índice agrupado y para volver a crear todos los índices no agrupados. Para obtener más información sobre el rendimiento de la carga masiva incremental en una tabla con índices agrupados, consulte "..." anteriormente en este documento. Para obtener más información sobre el rendimiento al borrar y volver a crear índices no agrupados, consulte la Figura 2 y 5 anteriormente en este documento.
Para el Plan C, el rendimiento de la carga masiva con todos los índices intactos es considerablemente menor que el rendimiento correspondiente en un montón. Como observación general, cuando el número de índices aumenta, el rendimiento de la carga disminuye considerablemente debido al conflicto de bloqueo. En las pruebas presentadas en este documento, se observó un ligero descenso del rendimiento de carga masiva al aumentar el tamaño de los datos existentes, como se ilustra en la Figura 8.

Figura 8 Rendimiento de la carga masiva incremental comparado con el tamaño de los datos existentes

Recomendaciones
Estas recomendaciones se aplican al tipo de carga de trabajo que se probó en el caso práctico presentado en este documento. Estas recomendaciones proporcionan un buen punto de partida para otros tipos de carga de trabajo.| • | Normalmente, las tablas de una aplicación DSS contienen varios índices, incluidos índices no agrupados, índices agrupados o ambos tipos de índices, para optimizar las consultas. Cuando aumenta el número de índices, el bloqueo se convierte en un problema de rendimiento más grave con comandos de carga masiva simultáneos. Por este motivo, se recomienda ejecutar un único comando de carga masiva en las tablas con varios índices. |
| • | Considere la posibilidad de conservar todos los índices durante la carga masiva incremental si el tamaño de los datos incrementales es menor que el uno por ciento del tamaño inicial de la tabla; en caso contrario, es mejor utilizar el Plan B. |
| • | Durante la carga masiva incremental con índices, a menos que los datos ya estén ordenados por la clave agrupada y se utilice una indicación de ordenación, los datos se ordenan antes de su inserción para mejorar la proporción de aciertos de caché durante la inserción fila a fila. El rendimiento que se obtiene al caber los datos del lote en la memoria física compensa el rendimiento que se pierde por la sobrecarga de abrir y cerrar el archivo. En la Figura 10 se ilustra cómo afecta el tamaño del lote al rendimiento medio de la carga (incluidas las fases de puesta en cola, ordenación e inserción) cuando se cargan datos en una tabla con un índice agrupado y siete índices no agrupados. Con un tamaño de lote mayor, la puesta en cola y ordenación de los datos se desborda de la memoria hasta tempdb, lo que requiere un mayor espacio para tempdb y un número suficiente de ejes de disco para las ordenaciones simultáneas en tempdb. Dado el tamaño y el ancho de banda de disco de tempdb para una aplicación DSS típica, esto no supone un gran problema. Una memoria física de gran tamaño mejorará el rendimiento, ya que se conservan más datos en memoria y se reduce la sobrecarga producida al abrir y cerrar el archivo. Figura 10 Carga masiva incremental en una tabla con un índice agrupado y siete índices no agrupados |
Apéndice A: Entornos de prueba
Servidor de base de datos principal: Hewlett Packard Proliant 8500| • | CPU: 8 procesadores con 733 MHz |
| • | RAM: 8 gigabytes (GB) |
| • | Adaptadores de bus de host (HBA): 4 HBA Emulex 952 |
Almacenamiento: Hewlett Packard Enterprise Virtual Array (EVA)
| • | Contenedores de almacenamiento: 2 |
| • | Controladoras: 4 |
| • | Discos: 168 discos con Fibre Channel de 72 GB y RPM de 10 kilobytes (KB) |
| • | 84 discos: Fibre Channel de 36 GB, RPM de 10 KB |
| • | Conmutador de red de área de almacenamiento (SAN): Brocade Silkworm 3800 |
| • | Dispositivo de administración SAN: Proliant DL380 |
Software
| • | Windows 2000 Advanced Server con Service Pack 3 |
| • | Microsoft SQL Server 2000 Enterprise Edition con Service Pack 3 |
Configuración de SQL Server
| • | AWE habilitado |
| • | La memoria máxima del servidor se estableció en 7 GB para permitir que SQL Server utilizara hasta 7 GB de memoria |
Datos y esquema de base de datos
Se utilizó un esquema de base de datos DSS representativo. Se utilizó la tabla de hechos como destino de la carga masiva. Los tipos de datos de la tabla incluyen int, money, datetime, char y varchar. Éste es el esquema de la tabla:
| • | Nombre de tabla: tabla_hechos |
| • | Columnas: Id_pedido int, Id_pieza int, Id_proveedor int, Nº_línea int, Precio money, Precio_venta money, Especial money, Impuestos money, Estado01 char(1), Estado02 char(1), FechaEnvío datetime, FechaConfirmación datetime, FechaRecepción datetime, Direcciones char (25), Comentarios varchar (40) General char(10) |
| • | Índice agrupado: ia: clave: (fechaEnvío) |
| • | Índice no agrupado: ina_1: clave: (id_pedido) |
| • | Índice no agrupado: ina_2: clave: (id_pieza, id_proveedor) |
| • | Índice no agrupado: ina_3: clave: (precio) |
| • | Índice no agrupado: ina_4: clave: (estado01) |
| • | Índice no agrupado: ina_5: clave: (fechaConfirmación) |
| • | Índice no agrupado: ina_6: clave: (fechaEnvío) |
| • | Índice no agrupado: ina_7: clave: (comentarios) |
| • | Ocho archivos sin formato con datos no ordenados y no exclusivos. |
Los datos existentes e incrementales se distribuyeron uniformemente por las claves de índice. Los rangos de datos se solapan bastante entre los archivos sin formato (por ejemplo, subprocesos de carga masiva) y entre los datos existentes y los datos incrementales.
Apéndice B: Predicción del punto de convergencia
El rendimiento de la carga masiva depende de distintos factores, como el esquema de la tabla, la distribución de los datos en la tabla de destino y los datos incrementales, la configuración del hardware y la carga de trabajo. No existe un número estándar válido para todas las situaciones. Sin embargo, si puede calcular el rendimiento de carga masiva en un conjunto de datos y un entorno representativos, podrá predecir, con bastante certeza, el punto de convergencia. En este apéndice se describe el modo de calcular el punto de convergencia con datos representativos.Tabla de destino con un índice agrupado
Paso 1: Recopile los datosLos datos que deben recopilarse para el experimento son:
| • | Tiempo de carga / tamaño de los datos sin índices (T sin índices): 22 seg/GB. |
| • | Tiempo de carga / tamaño de los datos con el índice agrupado (T con índice): 112 seg/GB. |
| • | Tiempo necesario para crear el índice / tamaño de tabla(ac): 45 seg/GB. |
| • | Tiempo necesario para borrar el índice / tamaño de tabla(ad): 114 seg/GB |
Puede realizar estos experimentos de referencia con una escala más pequeña o recopilar datos de cargas anteriores.
Paso 2: Calcule el tiempo para cada plan de ejecución
Suponga que tiene que cargar X cantidad de datos en una tabla con un tamaño de X0.
| • | Plan A: Realice la carga sin índices Como la velocidad de carga permanece constante en las tablas sin índices, el tiempo para cargar X cantidad de datos sin índices es igual a X * T sin índices. |
| • | Plan B: Realice la carga con el índice Como la velocidad de carga permanece constante en las tablas con un índice agrupado, el tiempo para cargar X cantidad de datos con el índice es igual a X * T con índice. Como el tiempo para borrar un índice agrupado en una tabla aumenta linealmente con el tamaño de los datos existentes en la tabla, el tiempo para borrar un índice en una tabla con un tamaño de X0 es igual a ad X0. Como el tiempo para crear un índice agrupado en una tabla aumenta linealmente con el tamaño de los datos existentes en la tabla, el tiempo para crear un índice en una tabla con un tamaño de X0 es igual a ac (X0 + X). Por tanto, el tiempo total para el plan B es X * T + ad X0 + ac (X0 + X). |
Paso 3: Pronostique el punto de convergencia para los planes de carga
En el punto de convergencia entre el Plan A y el Plan B,
X * T con índice = X * T sin índices + ad X0 + ac (X0 + X), de modo que
X / X0 = (ad + ac) / (T con índice – T sin índices - ac)
Si (T con índice – T - ac) < 0, no existe un punte de convergencia positivo, por lo que siempre será mejor cargar los datos con índices.
Cálculo del punto de convergencia con los datos de las pruebas presentadas en este documento:
X/ X0 = (114 + 45)/(112 – 22 – 45) = 350% (aproximadamente)
Este número fue el que se obtuvo en las pruebas presentadas en este documento. No es muy común plantearse que la tabla no estará disponible mientras se borra y se vuelve a crear el índice agrupado y se carga el 350 por ciento de datos adicionales. La carga de los datos con el índice agrupado es más favorable para la mayoría de los casos.
Tabla de destino con un índice no agrupado
Paso 1: Recopile los datosLos datos que deben recopilarse para el experimento son:
| • | Tiempo de carga / tamaño de los datos sin índices (T sin índices): 22 seg/GB. |
| • | Tiempo de carga / tamaño de los datos con el índice agrupado (T con índice): 99 seg/GB. |
| • | Tiempo necesario para crear el índice / tamaño de tabla(ac): 38 seg/GB. |
Puede realizar estos experimentos de referencia con una escala más pequeña o recopilar datos de cargas anteriores.
Paso 2: Calcule el tiempo para cada plan de ejecución
Suponga que tiene que cargar X cantidad de datos en una tabla con un tamaño de X0.
| • | Plan A: Realice la carga sin índices Como la velocidad de carga permanece constante en las tablas sin índices, el tiempo para cargar X cantidad de datos sin índices es igual a X * T sin índices. |
| • | Plan B: Realice la carga con los índices Como la velocidad de carga permanece constante en las tablas con un índice no agrupado, el tiempo para cargar X cantidad de datos con el índice no agrupado es igual a X * T con índice. Como el tiempo para crear un índice no agrupado en una tabla aumenta linealmente con el tamaño de los datos existentes en la tabla, el tiempo para crear un índice en una tabla con un tamaño de X0 es igual a ac (X0 + X). Por tanto, el tiempo total para el Plan A es X * T sin índices + ac (X0 + X). En este caso, el tiempo para crear el índice no agrupado no se tiene en cuenta porque es instantáneo. |
Paso 3: Pronostique el punto de convergencia para los planes de carga
En el punto de convergencia entre el Plan A y el Plan B,
X * T con índice = X * T sin índices + ac (X0 + X), de modo que
X / X0 = ac / (T con índice – T sin índices - ac)
Si T con índice – T sin índices - ac < 0, no existe ningún punto de convergencia positivo. En este caso, es siempre mejor cargar los datos con los índices.
Cálculo del punto de convergencia con los datos de las pruebas presentadas en este documento:
X/X0 = (38)/(99 – 22 – 38) = 38/39 = 100% (aproximadamente)
Este número fue el que se obtuvo en las pruebas presentadas en este documento. Sin el tiempo necesario para borrar los índices, puede ser conveniente borrar el índice no agrupado, si debe cargarse una cantidad bastante mayor de datos adicionales comparada con los datos existentes.
Tabla de destino con un índice agrupado y siete índices no agrupados:
Paso 1: Recopile los datosLos datos que deben recopilarse para el experimento son:
| • | Tiempo de carga / tamaño de los datos sin índices (T sin índices): 22 seg/GB. |
| • | Tiempo de carga / tamaño de los datos con todos los índices (T con todos los índices): 35.067 seg/GB. Nota sólo se utilizó la velocidad registrada con > 5 GB de datos existentes. |
| • | Tiempo de carga / tamaño de los datos con sólo los índices agrupados (T con el índice agrupado): 112 seg/GB. |
| • | Tiempo necesario para crear todos los índices / tamaño de tabla(ac todos): 324 seg/GB. |
| • | Tiempo necesario para crear todos los índices / tamaño de tabla(ac todos no agrupados): 362 seg/GB. |
| • | Tiempo necesario para borrar el índice agrupado / tamaño de tabla(ad): 114 seg/GB |
Puede realizar estos experimentos de referencia con una escala más pequeña o recopilar datos de cargas anteriores.
Paso 2: Calcule el tiempo para cada plan de ejecución
Suponga que tiene que cargar X cantidad de datos en una tabla con un tamaño de X0:
| • | Plan A: Realice la carga sin índices Como la velocidad de carga permanece constante en las tablas sin índices, el tiempo para cargar X cantidad de datos con índices es igual a X * T sin índices. Como el tiempo para borrar un índice agrupado en una tabla aumenta linealmente con el tamaño de los datos existentes en la tabla, el tiempo para borrar un índice en una tabla con un tamaño de X0 es igual a ad X0. Como el tiempo para crear un índice no agrupado o un índice agrupado en una tabla aumenta linealmente con el tamaño de los datos existentes en la tabla, el tiempo para crear un grupo de índices no agrupados y un índice agrupado aumenta linealmente con el tamaño de los datos existentes en la tabla, por lo que el tiempo para crear un índice en una tabla con un tamaño de X0 es igual a ac todos (X0 + X). Por tanto, el tiempo total para el Plan A es igual a X * T sin índices + ad X0 + ac todos (X0 + X). |
| • | Plan B: Realice la carga sólo con el índice agrupado Al igual que el Plan A, el tiempo total para el Plan B es igual a X * T con el índice agrupado + ac todos no agrupados (X0 + X). |
| • | Plan C: Realice la carga con el índice El tiempo para cargar X cantidad de datos con todos los índices es igual a X * T con todos los índices. |
Paso 3: Pronostique el punto de convergencia para los planes de carga
En el punto de convergencia entre el Plan A y el Plan B,
X * T con el índice agrupado + ac todos no agrupados (X0 + X) = X * T sin índices + ad X0 + ac todos (X0 + X).
X / X0 = (ad + ac todos) / (T con el índice agrupado – T sin índices - ac todos no agrupados)
En las pruebas presentadas en este documento, T con el índice agrupado – T sin índices - ac todos no agrupados < 0, por lo tanto siempre es mejor conservar el índice agrupado para la carga masiva que borrarlo, como lo corroboran las pruebas anteriores.
En el punto de convergencia entre el Plan B y el Plan C,
X * T con todos los índices = X * T con el índice agrupado + ac todos no agrupados (X0 + X), de modo que
X / X0 = ac todos no agrupados / T con todos los índices – T con el índice agrupado - ac todos).
Cálculo del punto de convergencia con los datos de las pruebas presentadas en este documento:
X/ X0 = (362) / (35.067 – 112 – 362) = 362/34.593 = 1% (aproximadamente)
Por tanto, el Plan B es mejor si los datos incrementales superan el uno por ciento de los datos existentes. En las pruebas presentadas en este documento, el punto de convergencia es aproximadamente el uno por ciento, como lo constatan las pruebas. Puede ser conveniente borrar los índices no agrupados y conservar el índice agrupado, a menos que haya que cargar una pequeña cantidad de datos adicionales en comparación con los datos existentes.
Conexión a Base de Datos SQL Server con ADO.Net
Antes de explicar todos estos asuntos se supone que el participante o la persona que hizo esta consulta en el blog debera estar familiarizado con los siguientes temas:
- Terminologia de Base de Datos
- SQL
PROGRAMACIÓN ADO.NET
LIBRERIAS DE DATOS
LIBRERIAS EMPRESARIALES DE DATOS
Esta tecnologia pertenece a la jerarquia de net framework en base a su nivel de coneccion a fuentes de informacion.
Contienen diferentes tipos de clases destinados a la conectividad y a la administracion de fuentes de informacion tanto internas como externas. La tecnologia ADO.NET es una base escencial para cualquier tipo de proyecto que requiera datos en una tecnologia de informacion.
Existe una librería jerarquica que es nativa de SQL SERVER para proveer la informacion de un conjunto de clases para la administracion de datos, ademas existen otras librerias no solamente para un motor de base de datos especifico sino tambien para otros motores de base de datos de distintas empresas.
La librería jerarquica a utilizar para la administracion de SQL SERVER es:
‘System.Data.SQLClient’: es una representacion nativa y proveedor de SQL SERVER.
MODOS DE ACCESO A TRAVES DE CONECCIONES
Para accesar a la fuente de informacion se establece dos modos de conecciones las cuales son:
coneccion abierta y coneccion cerrada; quiere decir que existen librerias que permiten utilizar el proveedor de datos para obtener o establecer informacion a una fuente o motor de base de datos sin necesidad de mantener abierto una coneccion. Existe otra librería que necesita de una coneccion abierta paraadministrar una fuente de informacion.
Primero tendriamos que crear un formulario con las siguientes caracteristicas como apreciamos en el pantallaso a continuacion:
Este primer ejemplo sera en "MODO DE CONEXION ABIERTA"

Aqui es donde visualizaremos los datos con los cuales amos accesar en el momento de la conexion con la Base de Datos SQL Server..........Usaremos la Base de Datos Neptuno la cual a venido siendo de nuestro uso en el transcurso de la enseñanza del BLOG.


Aqui ya estamos en el SQL Server con la siguiente sentencia la cual nos muestra la tabla Productos la cual mostraremos solo los suspendidos o con el valor a 1

Aqui vemos el codigo implementado para nosotros poder hacer tal conexion, con la respectia sentencia del que ejecutamos en el SQL Server, dicho sea de paso explicado en comentario cada linea de codigo y su respectivo uso.
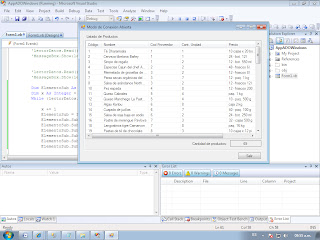
Aqui como podemos ver ya hicimos tal acceso a la Data mostrandome lo que pedi.

creamos el siguiente formulario


- Terminologia de Base de Datos
- SQL
PROGRAMACIÓN ADO.NET
LIBRERIAS DE DATOS
LIBRERIAS EMPRESARIALES DE DATOS
Esta tecnologia pertenece a la jerarquia de net framework en base a su nivel de coneccion a fuentes de informacion.
Contienen diferentes tipos de clases destinados a la conectividad y a la administracion de fuentes de informacion tanto internas como externas. La tecnologia ADO.NET es una base escencial para cualquier tipo de proyecto que requiera datos en una tecnologia de informacion.
Existe una librería jerarquica que es nativa de SQL SERVER para proveer la informacion de un conjunto de clases para la administracion de datos, ademas existen otras librerias no solamente para un motor de base de datos especifico sino tambien para otros motores de base de datos de distintas empresas.
La librería jerarquica a utilizar para la administracion de SQL SERVER es:
‘System.Data.SQLClient’: es una representacion nativa y proveedor de SQL SERVER.
MODOS DE ACCESO A TRAVES DE CONECCIONES
Para accesar a la fuente de informacion se establece dos modos de conecciones las cuales son:
coneccion abierta y coneccion cerrada; quiere decir que existen librerias que permiten utilizar el proveedor de datos para obtener o establecer informacion a una fuente o motor de base de datos sin necesidad de mantener abierto una coneccion. Existe otra librería que necesita de una coneccion abierta paraadministrar una fuente de informacion.
Primero tendriamos que crear un formulario con las siguientes caracteristicas como apreciamos en el pantallaso a continuacion:
Este primer ejemplo sera en "MODO DE CONEXION ABIERTA"

Aqui es donde visualizaremos los datos con los cuales amos accesar en el momento de la conexion con la Base de Datos SQL Server..........Usaremos la Base de Datos Neptuno la cual a venido siendo de nuestro uso en el transcurso de la enseñanza del BLOG.
Bueno para comenzar tubieramos que saber que un proveedor de datos de .NET Framework sirve para conectarse a una base de datos, ejecutar comandos y recuperar resultados. Estos datosa mencionados se procesan directamente o se colocan en un "DataSet" de ADO.Net con el fin de exponerlos al usuario para un proposito especifico, combinarlos con datos de varios origenes o utilizarlos de forma remota entre niveles.
Por ejemplo uno de estos proveedores para SQL Server seria el 'System.Data.SqlClient', el cual proporciona acceso de datos para Microsoft SQL Server 7.0 o posterior a esta version, que mas que todo vendria a ser como el NameSpaces o Espacio de nombres.
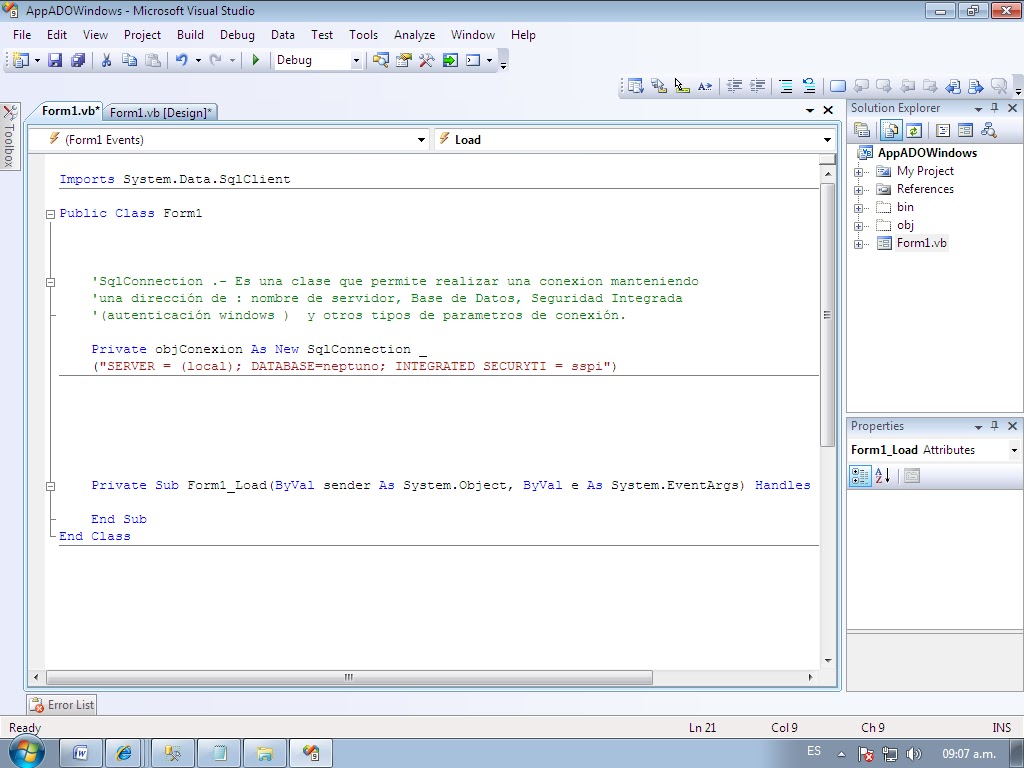
SqlConnection: es una clase que permite realizar una conexion manteniendo una direccion de: Nombre de Servidor, Base de Datos, Seguridad Integrada(Autentificación de Windows) y otros tipos de parametros de conexion. A continuacion les mostrare el uso de esta clase dentro de la programacion de ADO.Net, el cual se mostrara en pantallasos los cuales yo desarrolle en clases....
Por ejemplo uno de estos proveedores para SQL Server seria el 'System.Data.SqlClient', el cual proporciona acceso de datos para Microsoft SQL Server 7.0 o posterior a esta version, que mas que todo vendria a ser como el NameSpaces o Espacio de nombres.
SqlConnection: es una clase que permite realizar una conexion manteniendo una direccion de: Nombre de Servidor, Base de Datos, Seguridad Integrada(Autentificación de Windows) y otros tipos de parametros de conexion. A continuacion les mostrare el uso de esta clase dentro de la programacion de ADO.Net, el cual se mostrara en pantallasos los cuales yo desarrolle en clases....

Aqui ya estamos en el SQL Server con la siguiente sentencia la cual nos muestra la tabla Productos la cual mostraremos solo los suspendidos o con el valor a 1
Aqui vemos el codigo implementado para nosotros poder hacer tal conexion, con la respectia sentencia del que ejecutamos en el SQL Server, dicho sea de paso explicado en comentario cada linea de codigo y su respectivo uso.

Aqui como podemos ver ya hicimos tal acceso a la Data mostrandome lo que pedi.
Ahora les enseñare el codigo que use para tal conexion y cada linea de codigo con su respectiva explicacion:
Imports System.Data.SqlClient
Public Class Form1
'SqlConnection .- Es una clase que permite realizar una conexion manteniendo
'una dirección de : nombre de servidor, Base de Datos, Seguridad Integrada
'(autenticación windows ) y otros tipos de parametros de conexión.
Private objConexion As New SqlConnection _
("SERVER = (local); DATABASE=neptuno; INTEGRATED SECURITY = sspi")
Private Sub Form1_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load
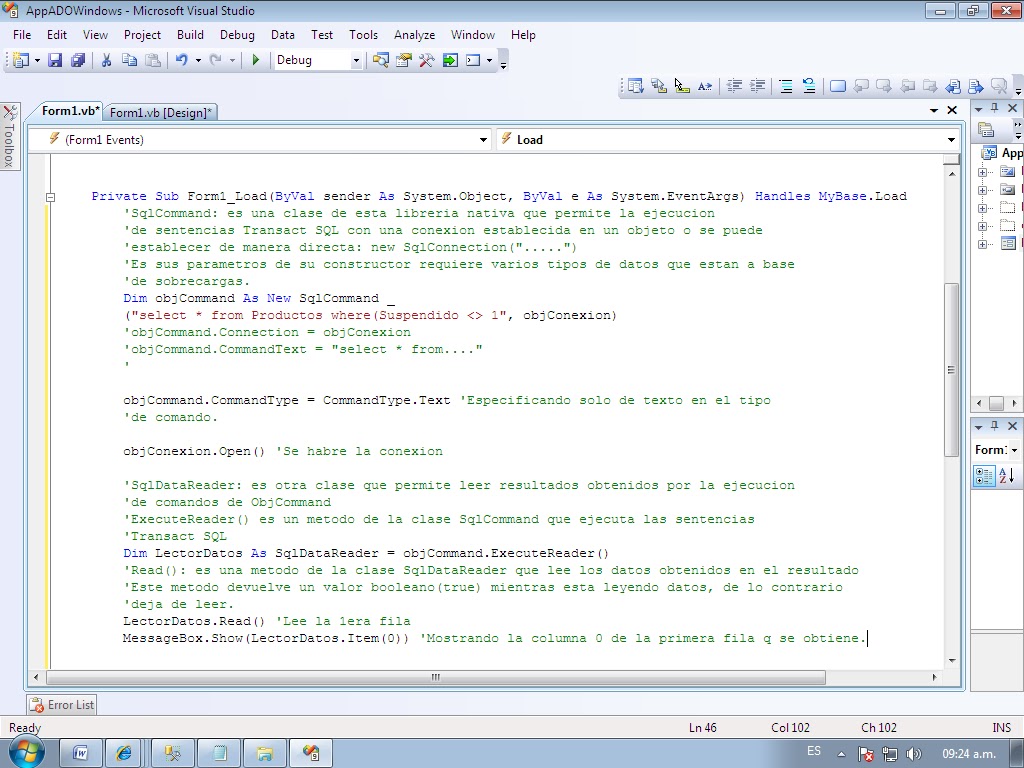
'SqlCommand .- Es una clase de ésta libreria nativa que permite la ejecucion
'de sentencias Transact SQL con una conexion establecida en un objecto o se puede
'establecer de manera directa: new SqlConnection("............")
'Es sus parámetros de su constructor requiere varios tipos de datos que estan a base de
'sobrecargas.
Dim objCommand As New SqlCommand _
("select * from Productos where Suspendido <> 1", objConexion)
'objCommand.Connection = objConexion
'objCommand.CommandText = "select * from......"
'
objCommand.CommandType = CommandType.Text 'Especificando sólo de Texto en el tipo
'de Comando.
objConexion.Open() 'Se habre la conexión
'SqlDataReader .- Es otra clase que permite leer resultados obtenidos por
'la ejecución de comandos de ObjCommand
'ExecuteReader() .- Es un método de la clase SqlCommand que ejecuta las sentencias
'transact(Sql)
Dim lectorDatos As SqlDataReader = objCommand.ExecuteReader()
'Read() .- Es un método de la clase SqlDataReader que lee los datos obtenidos en el resultado.
'Éste método devuelve un valor booleano (true) miestras esta leyendo datos, de lo contrario
'deja de leer.
EstructurarColumnasListView()
'lectorDatos.Read() 'Lee la primera fila
'MessageBox.Show(lectorDatos.Item(0)) 'Mostrando la columna 0 de la primera fila que se obtiene.
'lectorDatos.Read() 'Lee la siguiente fila
'MessageBox.Show(lectorDatos.Item(0))
Dim ElementoSub As ListViewItem
Dim x As Integer = 0
While (lectorDatos.Read()) 'Mientras esta leyendo.
x += 1
ElementoSub = ListaProducto.Items.Add(lectorDatos.Item(0))
ElementoSub.SubItems.Add(lectorDatos.Item(1))
ElementoSub.SubItems.Add(lectorDatos.Item(2))
ElementoSub.SubItems.Add(lectorDatos.Item(3))
ElementoSub.SubItems.Add(lectorDatos.Item(4))
ElementoSub.SubItems.Add(lectorDatos.Item(5))
ElementoSub.SubItems.Add(lectorDatos.Item(6))
End While
lblCantidad.Text = x
End Sub
Private Sub EstructurarColumnasListView()
ListaProducto.View = View.Details 'Va ser un control de grilla
ListaProducto.Columns.Add("Código", 50, HorizontalAlignment.Left)
ListaProducto.Columns.Add("Nombre", 150, HorizontalAlignment.Left)
ListaProducto.Columns.Add("Cod Proveedor", 100, HorizontalAlignment.Left)
ListaProducto.Columns.Add("Cant. Unidad", 150, HorizontalAlignment.Left)
ListaProducto.Columns.Add("Precio", 100, HorizontalAlignment.Left)
ListaProducto.Columns.Add("Unid. Existencia", 100, HorizontalAlignment.Left)
ListaProducto.GridLines = True ' Para tener las lineas tipo excel.
End Sub
End Class
Aqui en este segundo ejemplo mostraremos ahora con una conexion de MODO CERRADA:

creamos el siguiente formulario

A continuacion les pegare el codigo usado en dicho formulario dicho sea de paso indicarles que cada linea de codigo esta explicado para un mayor entendimiento de su parte.....
Imports System.Data.SqlClient
Public Class Form2
Private Sub Form2_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load
'SqlDataAdapter: Permite el uso de la fuente de informacion sin utilizar la
'conexion abierta. Va directamente como proveedor a servidor de SQL
'para obtener o establecer datos.
Dim objDataAdapter As New SqlDataAdapter _
("select * from Pedidos where RegionDestinatario is not null", Form1.objConexion)
'Data Table: es una clase que mantiene una coleccion de datos(filas y columnas)
'de manera temporal en la memoria del computador.
Dim ObjTablaPedidos As New DataTable("Pedidos") '("Pedidos") es una Alias a la tabla temporal.
'Fill(DataTable, Dataset): es una metodo que almacena datos a un objeto tabla temporal.
objDataAdapter.Fill(ObjTablaPedidos)
'DataSource: es una propiedad del control DataGridView que permite establecer u obtener
'recursos de datos de una tabla temporal.
ListaPedidos.DataSource = ObjTablaPedidos
'Nota: Solo algunos controles tienen esta propiedad.
End Sub
End Class

Aqui nos muestra los datos en MODO DE CONEXION CERRADA.
Suscribirse a:
Entradas (Atom)